The Relational Data Model
In the relational data model, a relation (table) can be thought as a set of records, like a table that contains information about employees in a company.
A record (row or tuple) represents a simgle item in a relation. Every row in the same relation has the same structure. For example, if, in the employees table, we can have a row that describes the employe named ‘Mike Smith’.
A field (column) represents a characteristic or variable of an entity described. For example, the field ‘salary’ can hold salaries for all the employees in the ‘employees’ table.
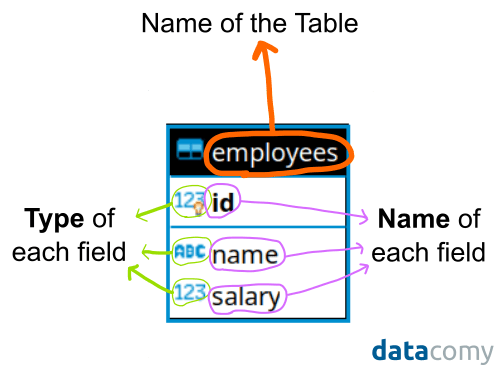
In the relational data model, a description of the data in a relation is called a schema. A schema for a relation specifies the following:
- the
nameof the relation (name of the table). - the
nameof each field (column names). - the
typeof each field (for example,stringfor name, andintegerfor salary).
In our case, the following schema could describe the employees relation:
Employees(id: integer, name: string, salary: integer`).

test=# \d employees
Table "public.employees"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------------------------------------
id | bigint | | not null | nextval('employees_id_seq'::regclass)
name | character varying(70) | | |
salary | integer | | |
Indexes:
"employees_pkey" PRIMARY KEY, btree (id)
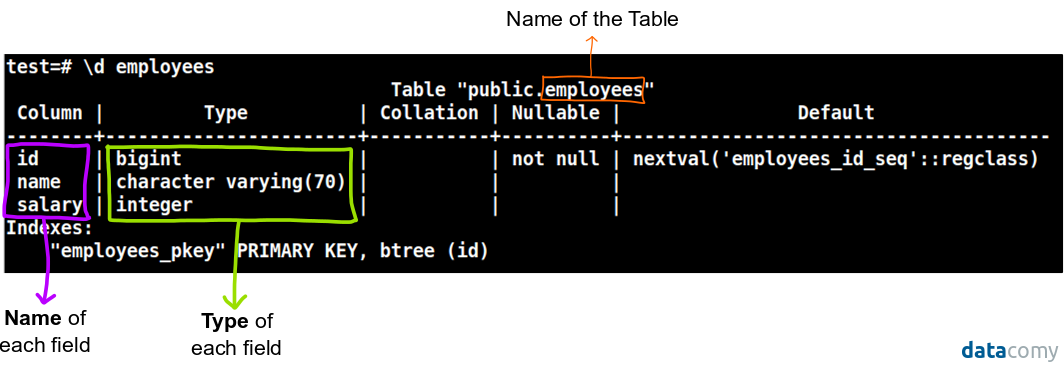
The previous images where taken from DBeaver, a SQL client software application and from the PostgreSQL command line.
Every row in the Employees table follows the same schema.

At the same time, in the same database we could have another relation with the following schema: customers(id: integer, name: string, email: string, phone: string).
test=# \d customers
Table "public.customers"
Column | Type | Collation | Nullable | Default
--------+--------+-----------+----------+---------
id | bigint | | |
name | text | | |
email | text | | |
phone | text | | |
Indexes:
"ix_customers_id" btree (id)
test=# select * from customers;
id | name | email | phone
----+--------+------------------+------------------
1 | Amelia | [email protected] | +44 20 1111 5678
2 | Oliver | [email protected] | +44 20 2222 5679
3 | Isla | [email protected] | +44 20 333 5680
4 | Harry | [email protected] | +44 20 4444 5681
5 | Ava | [email protected] | +44 20 5555 5682
(5 rows)
Integrity Constraints
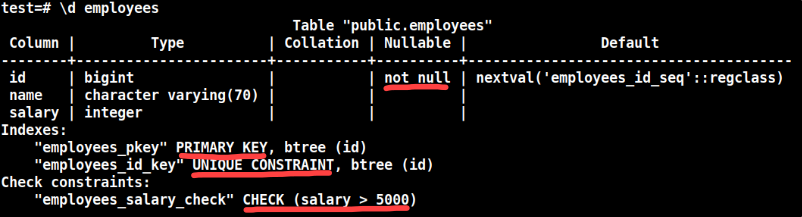
A schema can include constraints, called integrity constraints in the relational data model. This constraints make the schema more precise. For example, in the Employees relation, we could specify that each id must be unique, a maximum lenght for the name and minumum and maximum values for the salary.
Constraints are rules enforced on data columns. Constraints are used mainly to prevent invalid data from being entered into the database. This ensures the accuracy and reliability of the data in the database. For example, if we try to enter a salary of just two dollars, and we specified a minimum of $500, we will see an error when trying to enter an invalid value.
Regarding performace, in some cases, constraints can improve the performace of SQL queries, but in many cases, constraints can actually decrease performace, because the database engine has to check if the data adheres to the constraints.
Constraints
Source: Ramakrishan, Gehrke: Database Management Systems